Appearance
基于Dify部署AI工作流
0 主要瓶颈
- 多模态大模型的配置
- 知识库文件的数据处理和标准化
1 Dify介绍
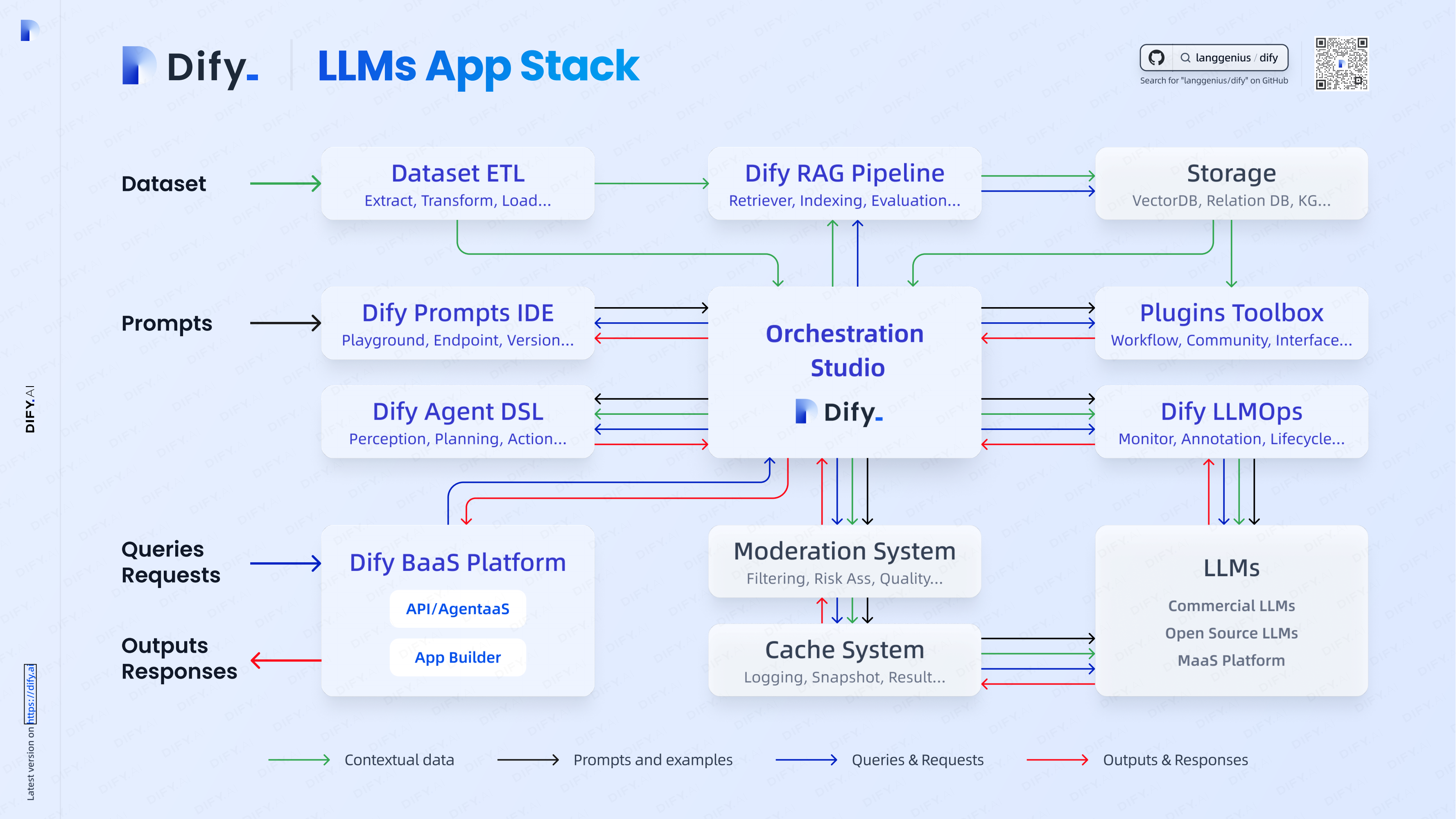
2 部署
Dify部署
- git clone代码
- /docker 内运行compose
- 如果拉取镜像失败,需要设置镜像加速(阿里云已转为内网使用,需要用其他源)
- 保证80端口没有被占用,否则Nginx服务无法启动
- 访问https://localhost
本地大模型部署
云端大模型配置
其他插件
SearXNG
3 知识库
结构化内容
向量化数据库选择
参数设置
父子检索模式
4 工作流
FAQ
- 工作流和Agent的区别
- 为什么要增加节点而不直接调用LLM
数据流动
主要变量数据流
常见节点设置
LLM
- 记忆:开启记忆后,会将上一次的回答作为上下文,与当前的问题一起发送给LLM,从而得到更好的回答。设置可看到的历史记录
- 温度:生成关键词更稳定,数值越低随机越低
知识检索
- TopK:引用条数
- Score阈值:引用质量
5 提示词
- 常用智能体提示词(如角色等)
- 常用输出格式
示例
提取关键内容
text
## 任务
请你将用户给定的问题进行提取关键内容,用于进行检索知识库内容。
## 输出
输出多个关键字或者关键句,关键字或关键句之间使用空格隔开,无需其他多余的文本。禁止直接回答用户的问题。生成回答
text
## 角色
你是一个专业的客服,擅长根据知识库内容进行回答用户的问题
## 背景
严格根据知识库内容回答用户问题,对于用户理解私有文档十分重要
## 任务
严格根据下面的知识库的内容进行回答用户的问题。
## 知识库
/上下文